Evaluation Overview
Evals give you a repeatable check of your LLM application's behavior. You replace guesswork with data, and catch regressions before you ship a change.
Evaluation runs across most of the AI engineering loop: you score live traces in production, turn interesting examples into datasets, run experiments to compare changes, and judge the results with manual or automated evaluators. It happens both online, on live production traces, and offline, before you ship a change.
Want to see it in action? Create a free account and explore Langfuse Evaluation in the interactive example project.
Getting Started
Start with the Core Concepts page. It explains how evaluators, scores, datasets, and experiments fit together in Langfuse, which makes the rest of the docs much easier to navigate.
Once you have that context, use the table below to find the right feature page:
| If you want to... | Use this Langfuse feature |
|---|---|
| Review and rate traces manually | Annotation Queues, Scores via UI |
| Collect feedback from your end users | User Feedback |
| Leave open-ended notes on traces | Text scores, Annotation Queues |
| Track recurring failure categories | Score configs, scores |
| Build a reusable set of test cases | Datasets |
| Compare prompt, model, or code changes side by side | Experiments via UI, Experiments via SDK |
| Block deploys on regressions | CI/CD experiments |
| Run deterministic checks | Code Evaluators |
| Automatically score live production traces | LLM-as-a-Judge, Scores via API/SDK |
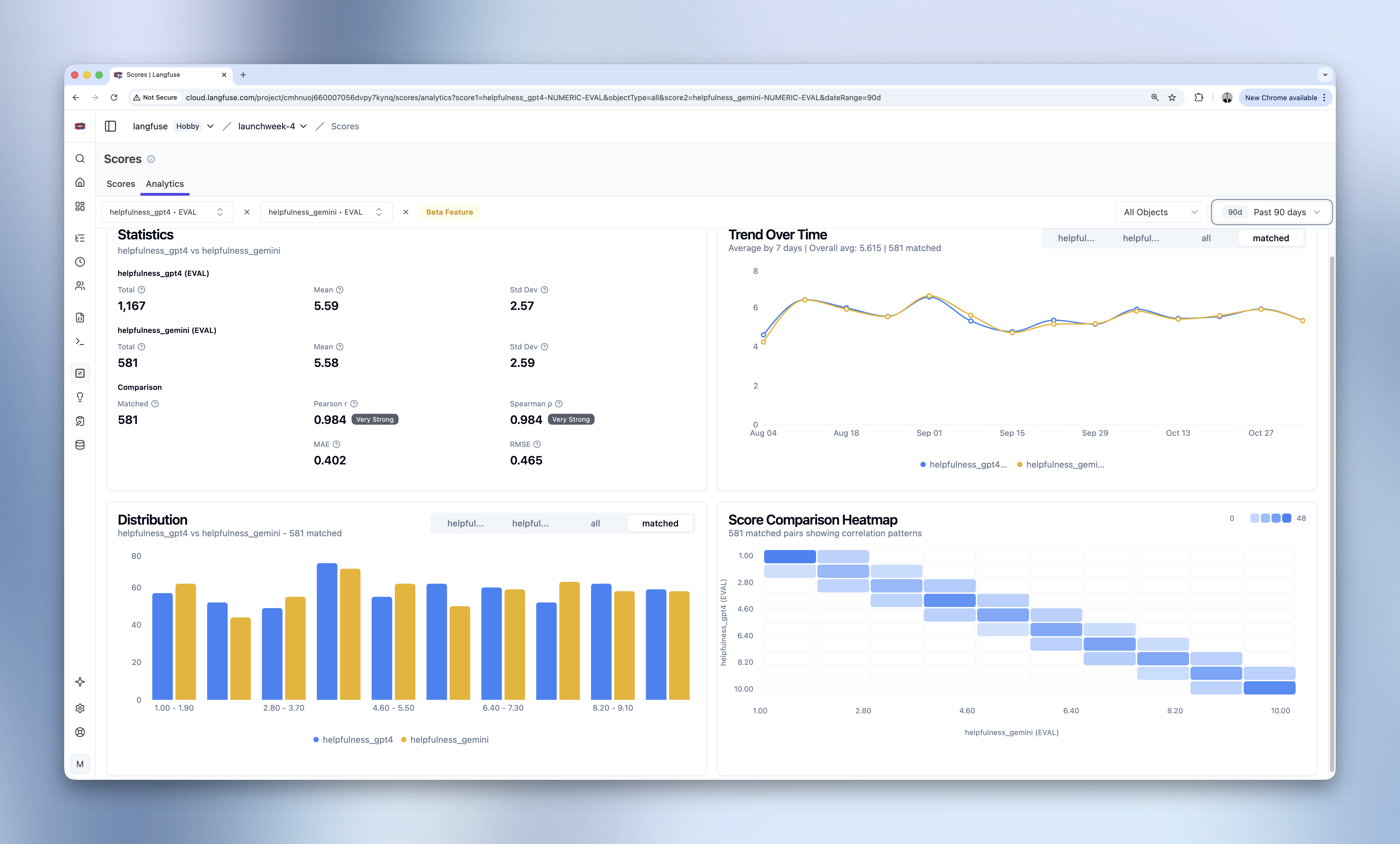
| See how scores trend over time | Score Analytics, custom dashboards |
Already know what you're looking for? Browse Evaluation Methods and Experiments in the sidebar.
GitHub Discussions
Last edited