Integrate Langfuse with Pydantic AI
This notebook provides a step-by-step guide on integrating Langfuse with Pydantic AI to achieve observability and debugging for your LLM applications.
About PydanticAI: PydanticAI is a Python agent framework designed to simplify the development of production-grade generative AI applications. It brings the same type-safety, ergonomic API design, and developer experience found in FastAPI to the world of GenAI app development.
What is Langfuse? Langfuse is an open-source LLM engineering platform. It offers tracing and monitoring capabilities for AI applications. Langfuse helps developers debug, analyze, and optimize their AI systems by providing detailed insights and integrating with a wide array of tools and Pydantic AIs through native integrations, OpenTelemetry, and dedicated SDKs.
Getting Started
Let’s walk through a practical example of using Pydantic AI and integrating it with Langfuse for comprehensive tracing.
Step 1: Install Dependencies
Note: This notebook utilizes the Langfuse OTel Python SDK v3. For users of Python SDK v2, please refer to our legacy Pydantic AI integration guide.
%pip install langfuse pydantic-ai -UStep 2: Configure Langfuse SDK
Next, set up your Langfuse API keys. You can get these keys by signing up for a free Langfuse Cloud account or by self-hosting Langfuse. These environment variables are essential for the Langfuse client to authenticate and send data to your Langfuse project.
import os
# Get keys for your project from the project settings page: https://cloud.langfuse.com
os.environ["LANGFUSE_PUBLIC_KEY"] = "pk-lf-..."
os.environ["LANGFUSE_SECRET_KEY"] = "sk-lf-..."
os.environ["LANGFUSE_HOST"] = "https://cloud.langfuse.com" # 🇪🇺 EU region
# os.environ["LANGFUSE_HOST"] = "https://us.cloud.langfuse.com" # 🇺🇸 US region
# Your OpenAI key
os.environ["OPENAI_API_KEY"] = "sk-proj-..." With the environment variables set, we can now initialize the Langfuse client. get_client() initializes the Langfuse client using the credentials provided in the environment variables.
from langfuse import get_client
langfuse = get_client()
# Verify connection
if langfuse.auth_check():
print("Langfuse client is authenticated and ready!")
else:
print("Authentication failed. Please check your credentials and host.")
Step 3: Initialize Pydantic AI Instrumentation
Now, we initialize the Pydantic AI Instrumentation. This automatically captures Pydantic AI operations and exports OpenTelemetry (OTel) spans to Langfuse.
from pydantic_ai.agent import Agent
# Initialize Pydantic AI instrumentation
Agent.instrument_all()Step 4: Basic Pydantic AI Application
Finally, run your Pydantic AI agent and generate trace data that will be sent to Langfuse. In the example below, the agent is executed with a dependency value (the winning square) and natural language input. The output from the tool function is then printed.
Make sure to pass instrument=True while configuring the Agent.
from pydantic_ai import Agent, RunContext
roulette_agent = Agent(
'openai:gpt-4o',
deps_type=int,
result_type=bool,
system_prompt=(
'Use the `roulette_wheel` function to see if the '
'customer has won based on the number they provide.'
),
instrument=True
)
@roulette_agent.tool
async def roulette_wheel(ctx: RunContext[int], square: int) -> str:
"""check if the square is a winner"""
return 'winner' if square == ctx.deps else 'loser'# Run the agent - using await since we're in a Jupyter notebook
success_number = 18
result = await roulette_agent.run('Put my money on square eighteen', deps=success_number)
print(result.output)Step 5: View Traces in Langfuse
After executing the application, navigate to your Langfuse Trace Table. You will find detailed traces of the application’s execution, providing insights into the LLM calls, retrieval operations, inputs, outputs, and performance metrics.
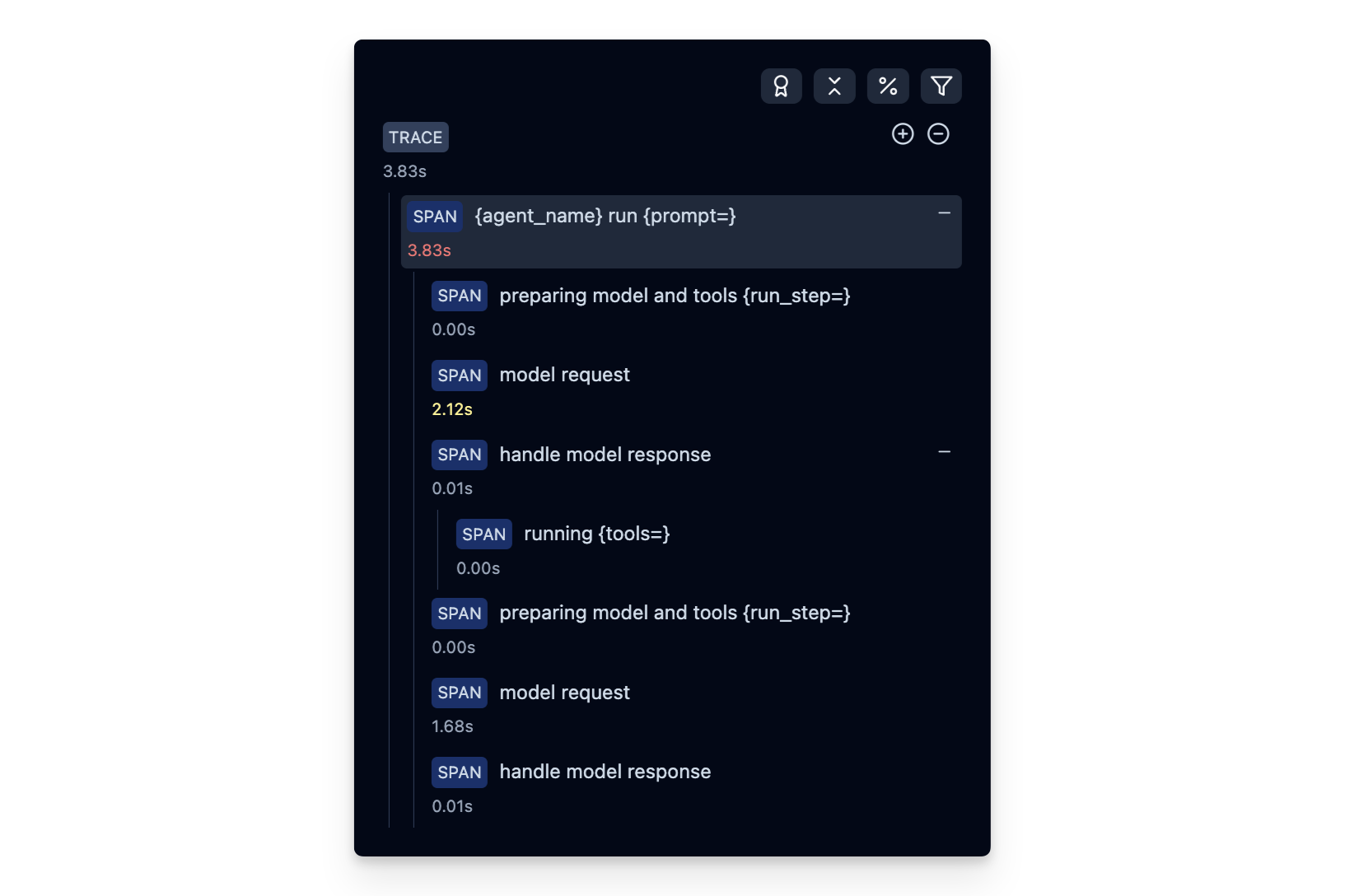
Interoperability with the Python SDK
You can use this integration together with the Langfuse Python SDK to add additional attributes to the trace.
The @observe() decorator provides a convenient way to automatically wrap your instrumented code and add additional attributes to the trace.
from langfuse import observe, get_client
langfuse = get_client()
@observe()
def my_instrumented_function(input):
output = my_llm_call(input)
langfuse.update_current_trace(
input=input,
output=output,
user_id="user_123",
session_id="session_abc",
tags=["agent", "my-trace"],
metadata={"email": "[email protected]"},
version="1.0.0"
)
return outputLearn more about using the Decorator in the Python SDK docs.
Next Steps
Once you have instrumented your code, you can manage, evaluate and debug your application: